THL Toolbox > Fonts & Related Issues > Tibetan Scripts, Fonts & Related Issues > Encoding Model of the Tibetan Script
Encoding Model of the Tibetan Script in the UCS
Contributor(s): Christopher Fynn
Anyone who needs to work with Tibetan or Dzongkha data on modern computer systems should have a basic grasp of how the Tibetan script is encoded in the Unicode Standard or UCS (Universal Character Set). Understanding the encoding model used for Tibetan characters is particularly important for those who need to create Tibetan web content, those writing software applications to handle Tibetan text, those want to create "smart" OpenType or AAT fonts for Tibetan, or those who want to understand how UCS Tibetan data is collated.
Regular & Combining Consonants
Vertically combined conjuncts of consonants and vowels occur frequently in Tibetan script text. However whether or not two neighboring characters should stack vertically or be written left to right, one following the next, cannot always be determined simply by applying contextual or grammatical rules. For this reason, as well as the frequency and complexity of these vertical conjuncts in Tibetan text, a model which is radically different from that adopted for Devanagari and other Indic scripts was adopted when the Tibetan script was encoded in the UCS.
The model adopted for encoding Tibetan is an explicitly stacking model based on Tibetan orthography or the layout of Tibetan glyphs - not on the rules of Tibetan grammar. In the UCS two complete sets of consonants are encoded as separate characters: one set of headline consonant characters (U+0F40-U+0F6A), to be used for single consonants or for the consonant occurring in the topmost position of any conjunct stack; and a second a set of combining consonant characters 1 (U+0F90 –U+0FBC) to be used for all additional consonants which occur in a stack. Characters for Tibetan vowels, usually written as marks combining with or dependant on consonants or consonant stacks, are encoded between these two sets of consonants (U+0F71-U+0FB1) in the UCS.
See: Table of Tibetan Characters in the UCS or:  Unicode chart of Tibetan Characters
Unicode chart of Tibetan Characters
Character Order
Conjunct stacks are usually encoded in the order which the parts are written, first the character for the consonant in the topmost or headline position, followed by characters for any combining consonants and then by the character(s) for any vowel(s):

Figure 1: Characters in the combination sgru
In this way it is possible to represent even very long stacks found in some religious texts:

Figure 2: Characters in the stack t+th+d+dh+n+ra
After the final below base letter has been written or entered, vowels or marks occurring above a base glyph are normally written or entered from the top of the first consonant upwards:
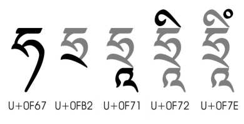
Figure 3: Order of characters in the combination hr'iM
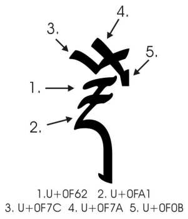
Figure 4: Order of characters in the combination rdoe
Reordering of Characters
Normalization processes may affect the order of Tibetan characters in a string 2 . In the Unicode Standard many characters have been assigned a series of property values for various purposes. In particular all combining characters have been assigned a canonical combining class value (CCCV). When a string is normalized, combining characters are re-ordered according to their canonical combining class value: those with a greater value being reordered after those with a smaller value. Characters with a CCCV of 0 are not re-ordered.
Certain Tibetan characters seem to have been assigned misappropriate values by the Unicode Technical Committee and, due to a strict policy of maintaining stability of the Standard, the UTC will not change these values.
In particular this means:
- The character U+0F39 TSA 'PHRU which would normally be written or entered immediately after the consonant with which it combines may get reordered after a vowel since it has a CCCV of 216 which is greater than the CCCVs assigned to vowels. As TSA 'PHRU is normally written before any vowel, and the shape and position of vowels may depend on whether a TSA 'PHRU has been added to the base consonant, it should have had a CCCV less than that of any combining vowel.
- In stacks with more than one vowel, the below base vowel U+0F74 VOWEL U – which would normally be written or entered before any above base vowel – may get reordered after them since this character has a CCCV of 132 while above base vowels have a CCCV of 130. The below base U+0F71 TIBETAN VOWEL SIGN AA has a CCV of 129 and so is not effected in this way.
- Anyone creating character to glyph lookups in fonts or sorting and string matching routines for Tibetan characters need to take into consideration the repercussions of such reordering and where necessary handle these in a way transparent to end users.
Syllables & Encoding
The basic unit of meaning or morpheme in Tibetan & Dzongkha is the tsheg bar usually referred to as a “syllable” in English books on Tibetan. Words consist of one or more these syllables.

Figure 5: Parts of the Tibetan syllable bsgrubs
Each syllable contains a root letter (ming zhi) and may additionally have any/or all of the following parts: prefix, head letter, sub-fixed letter, vowel sign, suffix, and post-suffix. Syllables are normally delimited by a tsheg or another punctuation character. There are normally no inter-word spaces in Tibetan.

Figure 6: Unicode characters in the Tibetan syllable bsgrubs
The base or root glyph in a Tibetan stack talked about when OpenType rendering for Tibetan should not be confused with the base or root letter (ming zhi) in a Tibetan syllable (tsheg bar).
Special Characters
U+0F0C Non breaking Tsheg
The properties defined for the normal TSHEG character (U+0F0B) in the Unicode Standard mean that text-processing applications may wrap a line after any occurrence of this character. In other words this character provides a line breaking opportunity. Sometimes, as in the case of a tsheg occurring after the letter nga and before a shad, it is desirable to suppress this behavior. In these cases, the non-breaking tsheg (U+0F0C) (inappropriately named "delimiter tsheg") may be used.
U+0F6A Fixed form Ra
The character FIXED FORM RA (U+0F6A) is used in place of RA (U+0F62) where it is necessary to override the normal contextual shaping of RA:

Figure 7: Shaping of Ra (0f62) and Fixed-form Ra (0F6A) when followed by combining sub-joined Tha
In dbu can script is not necessary to use FIXED FORM RA in combinations like RNYA in order to keep a full form ra mgo - since in dbu-can the normal contextual shaping of U+0F6A RA when followed by subjoined NYA is to retain its full form. Similarly when using a It should be noted that different styles of Tibetan script have different shaping rules:

Although they may occasionally indicate a lexical difference in Sanskrit words, the default behaviour of collation and text-matching algorithms should be to treat U+0F62 and U+0F6A as equivalent.
U+0FBA, U+0FBC, U+0FBD: Fixed form sub-joined WA, YA & RA
Similarly there are fixed form variants of the sub-joined consonant WA YA and RA. These should be used only where it is necessary to override normal contextual shaping behavior:

It is important to realize that 0FAD 0FB1 and 0FB2 should not always be rendered in short form. WA YA and RA occurring mid-stack are often normally written in their full form.
Fixed form characters are only required for certain Sanskrit combinations transcribed in Tibetan script and should be used where different letter forms appear in the original Sanskrit.
The default behavior of collation and text-matching algorithms should be to treat the characters U+0FAD / U+0FBA; U+0FB1/ U+0FBB and U+0FB2 / U+0FBC as equivalent.
U+0FC6 Tibetan Symbol padma gdan
This is an unusual combining symbol character - it may be used to combine with letters or other symbols.
This character would normally be entered after the sequence with which it combines:

Provided for unrestricted use by the Tibetan and Himalayan Library